밑바닥부터 시작하는 딥러닝 - YES24
직접 구현하고 움직여보며 익히는 가장 쉬운 딥러닝 입문서 이 책은 라이브러리나 프레임워크에 의존하지 않고, 딥러닝의 핵심을 ‘밑바닥부터’ 직접 만들어보며 즐겁게 배울 수 있는 본격 딥
www.yes24.com
1.
퍼셉트론을 파이썬으로 구현해보자.
먼저 AND 게이트를 구현해보자.
def AND(x1,x2):
w1,w2, theta = 0.5,0.5,0.7
tmp = x1*w1 + x2*w2
if tmp<= theta:
return 0
elif tmp > theta:
return 1매개변수 w1, w2, theta는 함수 안에서 초기화하고, 가중치를 곱한 입력의 총합이 임계값(theta)을 넘으면 1을 반환하고 그 외에는 0을 반환한다.
def AND(x1,x2):
w1,w2, theta = 0.5,0.5,0.7
tmp = x1*w1 + x2*w2
if tmp<= theta:
return 0
elif tmp > theta:
return 1
print(AND(0,0))
print(AND(1,0))
print(AND(0,1))
print(AND(1,1))<출력값>
0
0
0
1
2.
퍼셉트론의 동작원리는 다음과 같다.

x1,x2는 입력신호, y는 출력신호, w1,w2는 가중치(weight)이다.
그런데 여기서 임계값을 의미하는 θ를 -b로 치환하면 퍼셉트론의 동작을 아래와 같이도 쓸 수 있다.
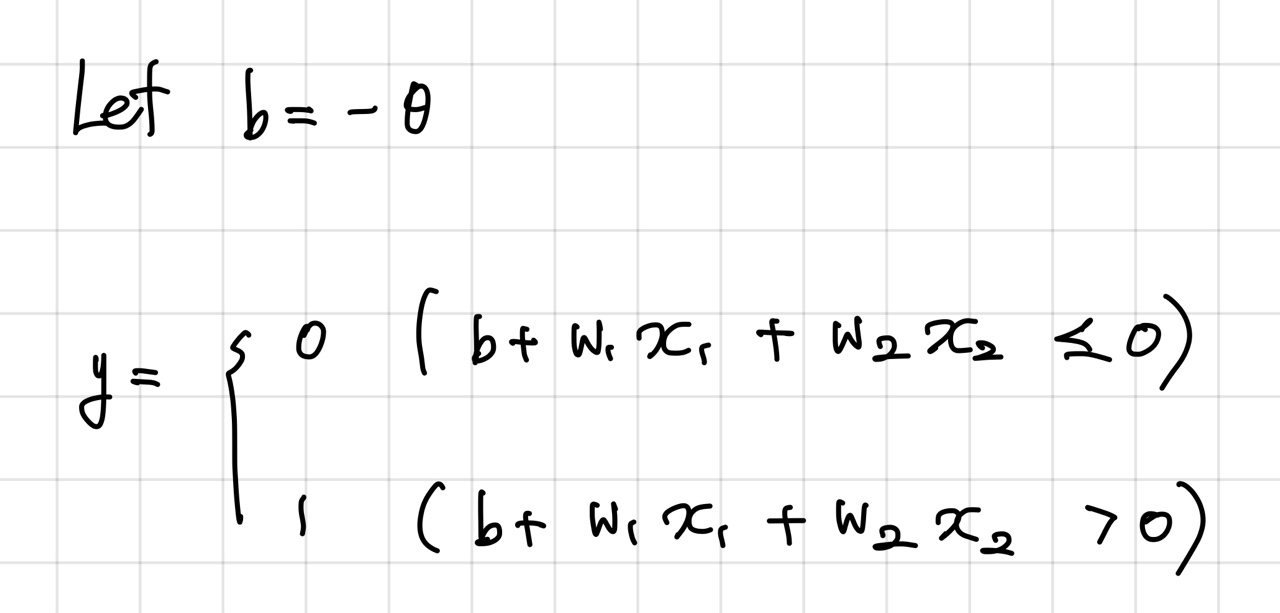
여기서 b를 편향(bias)라고 한다.
퍼셉트론은 입력 신호에 가중치를 곱한 값과 편향을 합하여, 그 값이 0을 넘으면 1을 출력하고 그렇지 않으면 0을 출력한다.
import numpy as np
x= np.array([0,1]) #입력
w = np.array([0.5,0.5]) #가중치
b = -0.7 #편향
print(w*x)
print(np.sum(w*x))
print(np.sum(w*x)+b)
<출력값>
[0. 0.5]
0.5
-0.19999999999999996 #대락 -0.2 (부동소수점 수에 의한 연산 오차)
왜 넘파이 배열로 곱셈을 하는지 알것 같다.
넘파이 배열끼리의 곱셈은 두 배열의 원소 수가 같다면 각 원소끼리 곱한다. 그래서 w*x에서도 인덱스가 같은 원소끼리 곱한다. 0*0.5를 하고 1*0.5를 한다.
그리고 np.sum() 메소드는 입력한 배열에 담긴 모든 원소의 총합을 계산한다.
이걸 만약 넘파이를 쓰지 않고 일반적인 파이썬 문법으로 해본다면?
궁금해서 시간까지 측정하며 해보려고 한다.
물론 아주 간단한 코드이기에 시간 차이가 크진 않겠지만..
x= [0,1]
w= [0.5,0.5]
b = -0.7
list_wx = []
for i in range(len(x)):
list_wx.append(x[i]*w[i])
print(list_wx)
print(sum(list_wx))
print(sum(list_wx)+b)<결과값>
[0.0, 0.5]
0.5
-0.19999999999999996출력값은 numpy 배열을 썼을 때와 동일하게 나온다.
그러면 시간은 얼마나 차이날까?
https://opentutorials.org/module/2980/17436
코드 실행시간 측정 - 파이썬_실전 프로젝트
문제를 풀다 보면, 실행 시간이 오래 걸리는 문제들이 간혹 있었습니다. 코드의 실행속도를 높일려면, 일단 시간을 측정해보는게 좋습니다. 시간 측정 코드 import time start = time.time() # 시작 시간
opentutorials.org
여기를 참고하여 실행시간을 측정하였다.
먼저 numpy 배열을 이용한 것의 시간은?
import time
start = time.time() # 시작 시간 저장
import numpy as np
x= np.array([0,1]) #입력
w = np.array([0.5,0.5]) #가중치
b = -0.7 #편향
print(w*x)
print(np.sum(w*x))
print(np.sum(w*x)+b)
print("time :", time.time() - start) # 현재시각 - 시작시간 = 실행 시간<출력값>
[0. 0.5]
0.5
-0.19999999999999996
time : 0.1568901538848877
그다음 numpy 배열을 사용하지 않고 한 것의 시간은?
import time
start = time.time() # 시작 시간 저장
x= [0,1]
w= [0.5,0.5]
b = -0.7
list_wx = []
for i in range(len(x)):
list_wx.append(x[i]*w[i])
print(list_wx)
print(sum(list_wx))
print(sum(list_wx)+b)
print("time :", time.time() - start) # 현재시각 - 시작시간 = 실행 시간<결과값>
[0.0, 0.5]
0.5
-0.19999999999999996
time : 0.0010001659393310547
오잉?
생각한 것과 달라서 좀 놀랐다..ㅋㅋ
numpy를 사용하지 않은 것이 덜 걸린다...
외장함수를 불러올 일이 없어서 그런건가?
그래도 암튼 numpy를 쓰는 이유가 다 있을 것이다.
그럴 것이라 믿으며 다음 단계로 넘어가야겠다!!!
3.
가중치와 편향을 도입한 AND 게이트를 구현해보자.
import numpy as np
def AND(x1,x2):
x = np.array([x1,x2])
w = np.array([0.5,0.5])
b = -0.7
tmp = np.sum(w*x) + b
if tmp <=0:
return 0
else:
return 1
w1과 w2는 각 입력 신호가 결과에 주는 영향력(중요도)을 조절하는 매개변수고,
편향(bias)은 뉴런이 얼마나 쉽게 활성화(결과로 1을 출력) 하느냐를 조정하는 매개변수이다.
예를 들어 b가 -0.1이면 각 입력 신호에 가중치를 곱한 값들의 합이 0.1을 초과할 때에만 뉴런이 활성화된다.
그런데 b가 -20.0이면 각 입력 신호에 가중치를 곱한 값들의 합이 20.0을 넘지 않으면 뉴런은 활성화하지 않는다.
책에서는 문맥에 따라 w1,w2,b를 모두 가중치라고 할 때도 있다.
그러나 보통은 w1,w2는 가중치로, b는 편향으로 서로 구별한다.
4.
NAND 게이트는 AND 게이트와 가중치(w와 b)만 다르다.
NAND 게이트가 특히 헷갈렸다.
5.
AND 게이트를 구현하는 매개변수의 부호를 모두 반전하기만 하면 NAND 게이트가 된다.
NAND 게이트를 구현해보자.
import numpy as np
def NAND(x1,x2):
x= np.array([x1,x2])
w = np.array([-0.5,-0.5]) #AND와는 가중치(w와 b)만 다르다.
b= 0.7
tmp = np.sum(w*x) +b
if tmp <= 0:
return 0
else:
return 1
print(NAND(0,0))
print(NAND(1,0))
print(NAND(0,1))
print(NAND(1,1))<출력값>
1
1
1
0
6.
OR 게이트도 구현해보자.
0,0을 넣었을 때에만 0을 반환하는 게이트를 만들면 된다.
import numpy as np
def OR(x1,x2):
x = np.array([x1,x2])
w = np.array([0.5,0.5])
b= -0.2
tmp = np.sum(w*x)+b
if tmp<=0:
return 0
else:
return 1
print(OR(0,0))
print(OR(1,0))
print(OR(0,1))
print(OR(1,1))<출력값>
0
1
1
1
7.
AND, NAND, OR 은 모두 같은 구조의 퍼셉트론이다.
차이는 가중치 w1,w2와 편향 b의 값 뿐이다.
파이썬으로 작성한 각각의 게이트에서도 다른 점은 가중치와 편향 값을 설정하는 부분뿐이다.
8.
단층 퍼셉트론으로는 비선형 영역을 분리할 수 없다.
그래서 단층 퍼셉트론으로는 XOR 게이트를 표현할 수 없고
따라서 퍼셉트론의 층을 쌓아서 XOR 게이트를 구현해야 한다.
9.
XOR 게이트를 구현하려면 AND, NAND, OR 게이트를 어떻게 구현해야 할까?
그래서 직접 다 해봤다.

x1, x2가 NAND와 OR 게이트의 입력이 되고, NAND와 OR의 출력이 AND 게이트의 입력으로 이어지면 XOR 게이트의 구현이 가능해진다.
10.
위에서 정의한 함수 AND,NAND, OR의 XOR 게이트를 구현해보자.
import numpy as np
def AND(x1,x2):
x = np.array([x1,x2])
w = np.array([0.5,0.5])
b = -0.7
tmp = np.sum(w*x) + b
if tmp <=0:
return 0
else:
return 1
def NAND(x1,x2):
x= np.array([x1,x2])
w = np.array([-0.5,-0.5]) #AND와는 가중치(w와 b)만 다르다.
b= 0.7
tmp = np.sum(w*x) +b
if tmp <= 0:
return 0
else:
return 1
def OR(x1,x2):
x = np.array([x1,x2])
w = np.array([0.5,0.5])
b= -0.2
tmp = np.sum(w*x)+b
if tmp<=0:
return 0
else:
return 1
def XOR(x1,x2):
s1 = NAND(x1,x2)
s2 = OR(x1,x2)
y = AND(s1,s2)
return y
print(XOR(0,0))
print(XOR(1,0))
print(XOR(0,1))
print(XOR(1,1))<출력값>
0
1
1
0
'Deep Learning' 카테고리의 다른 글
| [Deep Learning] 220806 학습일기 (0) | 2022.08.08 |
|---|---|
| [Deep Learning] 220805 학습일기 (0) | 2022.08.05 |
| [Deep Learning] 220730 학습일기 (0) | 2022.07.30 |
| [Deep Learning] 220729 학습일기 (0) | 2022.07.30 |
| [Deep Learning] 220727 학습일기 (0) | 2022.07.29 |



